Slurm trên FPT Cloud
FPT Managed GPU Cluster dựa trên nền tảng mã nguồn mở Kubernetes, giúp tự động hoá triển khai, nhân rộng và quản lý các ứng dụng container. FPT Managed GPU Cluster tích hợp đầy đủ các thành phần: Container Orchestration, Storage, Networking, Security, PaaS — cung cấp cho khách hàng môi trường tốt nhất để phát triển và triển khai ứng dụng trên cloud.
FPT Managed GPU Cluster là mô hình cung cấp dịch vụ Managed GPU Cluster của FKE. Với Managed GPU Cluster, FPT Cloud quản trị toàn bộ thành phần control-plane, người sử dụng sẽ triển khai và quản trị các Worker Node. Managed GPU Cluster giúp người sử dụng tập trung vào việc triển khai ứng dụng mà không cần tốn nguồn lực vào việc quản trị Kubernetes Cluster.
FPT Managed GPU Cluster là mô hình dịch vụ dựa trên nền tảng mã nguồn mở Kubernetes, giúp tự động hoá triển khai, nhân rộng và quản lý các ứng dụng đã được container hoá. Ngoài việc tích hợp đầy đủ các thành phần Container Orchestration, Storage, Networking, Security, PaaS, FPT Managed GPU Cluster còn cung cấp tài nguyên GPU, giúp hỗ trợ các thao tác tính toán phức tạp.
Những điều cần lưu ý trước khi sử dụng Managed GPU Cluster:
- Vị trí đặt Managed GPU Cluster: Vị trí địa lý (Region) có thể ảnh hưởng đến tốc độ truy cập đến máy chủ trong quá trình sử dụng. Bạn nên chọn Region gần nhất với đối tượng phát sinh traffic để tối ưu tốc độ.
- Số lượng các node và cấu hình của từng node cần sử dụng: Các tài khoản FPT Cloud đều được cấp một hạn mức nhất định cho các tài nguyên RAM, CPU, Storage, IP… Vì vậy, khách hàng nên xác định số lượng tài nguyên cần sử dụng và giới hạn tối đa cần đáp ứng để FPT Cloud hỗ trợ bạn tốt nhất.
1. Giới thiệu Slurm và Slurm trên Kubernetes
1.1 Giới thiệu Slurm
Slurm là một nền tảng mã nguồn mở mạnh mẽ dùng để quản lý tài nguyên cụm và lập lịch công việc (job). Nó được thiết kế nhằm tối ưu hiệu năng và hiệu quả cho các siêu máy tính và cụm tính toán lớn. Các thành phần chính của Slurm hoạt động cùng nhau để đảm bảo hệ thống đạt hiệu suất cao và tính linh hoạt. Hình sau đây minh họa cách thức hoạt động của Slurm.
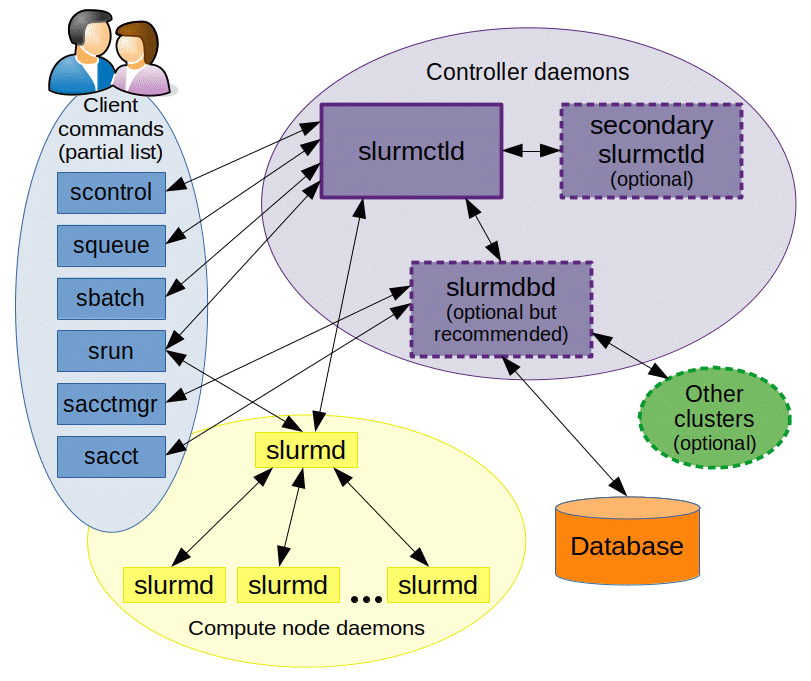
slurmctld: trình nền điều khiển của Slurm. Được xem như "bộ não" của Slurm, slurmctld giám sát tài nguyên hệ thống, lập lịch job và quản lý trạng thái cụm. Để tăng tính tin cậy, bạn có thể cấu hình một slurmctld thứ cấp nhằm tránh gián đoạn dịch vụ nếu slurmctld chính gặp sự cố, đảm bảo hệ thống luôn sẵn sàng cao.
slurmd: trình nền nút của Slurm. slurmd được triển khai trên mỗi nút tính toán. Nó nhận lệnh từ slurmctld và quản lý job, bao gồm khởi chạy và thực thi job, báo cáo trạng thái job và chuẩn bị cho các lệnh job mới. slurmd đóng vai trò giao diện để giao tiếp trực tiếp với tài nguyên tính toán và là cơ sở để lập lịch job.
slurmdbd: trình nền cơ sở dữ liệu của Slurm. slurmdbd là thành phần tùy chọn nhưng rất quan trọng cho quản lý lâu dài và kiểm toán trong các cụm lớn, vì nó duy trì một cơ sở dữ liệu tập trung để lưu lịch sử job và thông tin kế toán. slurmdbd có thể tổng hợp dữ liệu từ nhiều cụm do Slurm quản lý, giúp đơn giản hóa và nâng cao hiệu quả quản lý dữ liệu.
Slurm CLI: cung cấp các lệnh sau để hỗ trợ quản lý job và giám sát hệ thống:
scontrol: quản lý cụm và điều khiển cấu hình cụm.squeue: truy vấn trạng thái job trong hàng đợi.srun: gửi và quản lý job.sbatch: gửi job theo lô, giúp bạn lập lịch và quản lý tài nguyên tính toán.sinfo: truy vấn trạng thái chung của cụm, bao gồm tình trạng sẵn sàng của các nút.
1.2 Vì sao chạy Slurm trên Kubernetes?
Cả Slurm và Kubernetes đều có thể đóng vai trò là hệ thống quản lý tải công việc cho huấn luyện mô hình phân tán và tính toán hiệu năng cao (HPC) nói chung.
Mỗi hệ thống đều có điểm mạnh và điểm yếu riêng, và việc đánh đổi giữa chúng là đáng kể. Slurm cung cấp khả năng lập lịch tiên tiến, hiệu quả, kiểm soát phần cứng chi tiết và khả năng kế toán, nhưng lại thiếu tính phổ quát. Ngược lại, Kubernetes có thể được sử dụng cho nhiều mục đích khác ngoài huấn luyện (ví dụ: inferencing) và cung cấp khả năng tự động mở rộng và tự phục hồi tốt.
Hiện chưa có cách nào để kết hợp hoàn hảo lợi ích của cả hai giải pháp này. Và vì nhiều công ty công nghệ lớn sử dụng Kubernetes như một lớp hạ tầng mặc định mà không hỗ trợ hệ thống huấn luyện mô hình chuyên dụng, nên một số kỹ sư ML thậm chí không có lựa chọn.
Việc sử dụng Slurm trên Kubernetes cho phép chúng ta tái sử dụng khả năng tự động mở rộng và tự phục hồi của Kubernetes trong Slurm, đồng thời triển khai một số tính năng độc đáo, mà vẫn giữ nguyên cách tương tác quen thuộc với hệ thống.
1.3 Giới thiệu Slurm trên FPT Cloud Managed GPU/Kubernetes cluster
Slurm Operator sử dụng tài nguyên tùy chỉnh SlurmCluster (CR) để định nghĩa các tập tin cấu hình cần thiết cho việc quản lý các cụm Slurm và giải quyết các vấn đề liên quan đến quản lý tầng điều khiển. Điều này giúp đơn giản hóa việc triển khai và bảo trì các cụm được quản lý bởi Slurm. Hình dưới đây mô tả kiến trúc của Slurm trên FPT Cloud Managed GPU/Kubernetes cluster. Quản trị viên cụm có thể triển khai và quản lý một cụm Slurm thông qua SlurmCluster. Slurm Operator sẽ tạo các thành phần điều khiển của Slurm trong cụm dựa trên SlurmCluster. Một tập tin cấu hình Slurm có thể được gắn vào thành phần điều khiển thông qua một volume chia sẻ hoặc một ConfigMap.
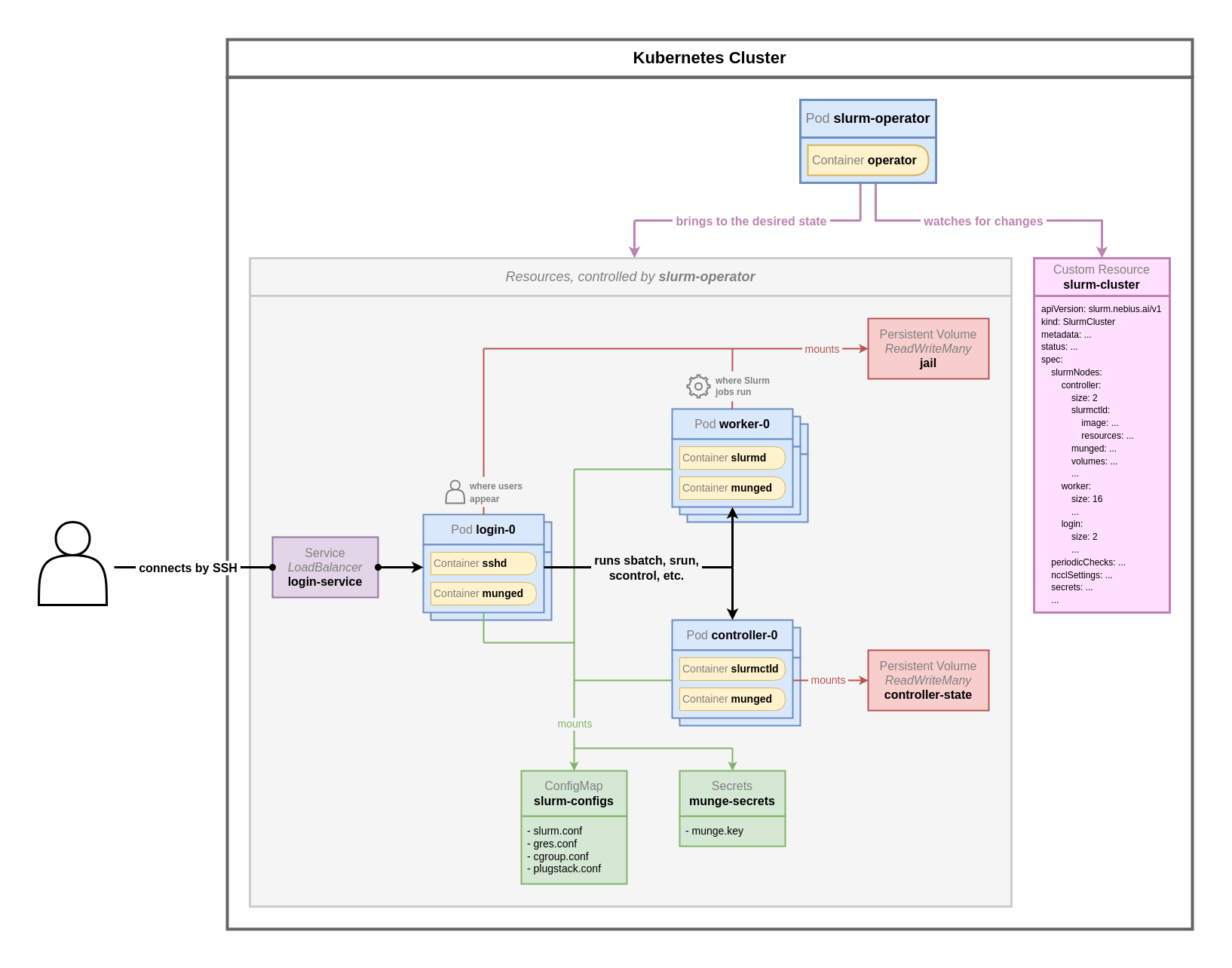
Trong mô hình triển khai Slurm on Kubernetes, các thành phần của một cụm Slurm như login node, worker node, ... được biểu diễn thành các Pod trên Kubernetes. Đồng thời, trong mô hình này, khái niệm shared-root volume được áp dụng — hiểu đơn giản, chúng ta triển khai một shared filesystem tương đương với file system của một OS, mọi job sau khi được chuyển đến worker node sẽ đều được triển khai trên môi trường shared root volume này. Điều này đảm bảo rằng mọi worker node sẽ luôn có cấu hình, các package và trạng thái giống nhau mà không cần quản lý thủ công. Nói cách khác, khi bạn cài đặt package trên một node, các package đó sẽ tự động xuất hiện trên các node còn lại.
Tất cả những gì bạn cần làm là định nghĩa cụm Slurm mong muốn của bạn tại Slurm cluster custom resource. Slurm Operator sẽ thực hiện việc triển khai và quản lý cụm Slurm thay cho bạn theo đúng trạng thái bạn đã định nghĩa ở Slurm cluster CR.
2. Hướng dẫn cài đặt
2.1 Hướng dẫn triển khai cụm Slurm trên Kubernetes
Yêu cầu bắt buộc:
- Cụm Kubernetes có thể sử dụng tính năng dynamic provisioning volume và còn dư quota storage.
- Ít nhất một StorageClass có thể cấp volume dạng ReadWriteMany.
Bước 1: Cài đặt Slurm Operator, GPU Operator, Network Operator tại phần cài đặt GPU software và chờ cho đến khi trạng thái các phần này ở ready.
Bước 2: Tại cụm Kubernetes, tạo sẵn các Persistent Volume để chứa shared root space và dữ liệu của controller node.
Hãy chú ý về các volume trong mô hình triển khai Slurm on Kubernetes:
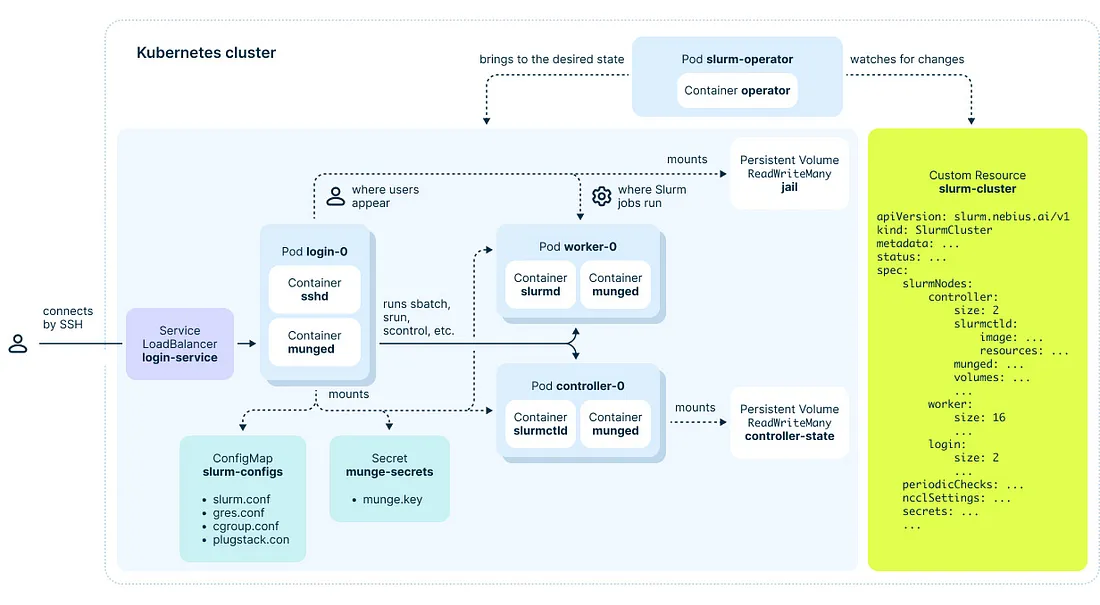
Trong đó:
- jail-pvc: mount vào worker node và login node, đóng vai trò như một shared sandbox, là môi trường các job được thực thi, cũng là môi trường user thao tác. Dung lượng volume này ít nhất là 40Gi để chứa file system của một OS.
- controller-spool-pvc: lưu thông tin cấu hình về cụm, đặt tại controller node.
jail-pvc.yaml:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: jail-pvc
namespace: fpt-hpc
spec:
storageClassName: default
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi
controller-spool-pvc.yaml (không cần tạo với Slurm Operator version >= 2.0.0):
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: controller-spool-pvc
namespace: fpt-hpc
spec:
storageClassName: default
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
Lưu ý:
- Các volume này đều là volume bắt buộc phải có, đều cần cung cấp cơ chế ReadWriteMany và tên của các PVC này phải giữ nguyên như trên.
- Nhằm thuận tiện để triển khai, chúng tôi đã sử dụng cơ chế dynamic provisioning volume trên sản phẩm FPT Cloud Managed Kubernetes.
- Với môi trường production, chúng tôi khuyến nghị việc mount root volume từ một phân vùng tĩnh thuộc file server, để thuận tiện cho việc migrate và bảo trì cụm Slurm.
Bước 3: Download Slurm cluster CR Helm chart và định nghĩa cấu hình mong muốn.
helm repo add xplat-fke https://registry.fke.fptcloud.com/chartrepo/xplat-fke
helm repo update
helm repo list
helm search repo slurm
helm pull xplat-fke/helm-slurm-cluster --version 1.14.10 --untar=true
Lưu ý: chỉnh version của slurm-cluster đúng với version của Slurm Operator.
Để tìm hiểu sâu hơn về các tham số của một cụm Slurm, chúng tôi khuyến khích bạn đọc phần 3: mô tả các tham số cụm Slurm.
cd helm-slurm-cluster/
vi values.yaml
Tại file values.yaml của folder vừa tải, bạn cần chỉnh một số trường quan trọng như:
| Tên trường | Mô tả |
|---|---|
slurmNodes.worker.size | Số lượng worker node |
slurmNodes.worker.size.spool.volumeClaimTemplateSpec.storageClassName | StorageClass của Persistent Volume dùng để lưu trạng thái worker node |
slurmNode.login.sshRootPublicKeys | Danh sách các public key của user root trong cụm Slurm |
SlurmNode.accounting.mariadbOperator.storage.volumeClaimTemplate.storageClassName | StorageClass của Persistent Volume dùng để lưu dữ liệu tại slurmdbd node |
Sau khi chỉnh cấu hình cụm theo nhu cầu, chạy lệnh sau:
helm install fpt-hpc ./ -n fpt-hpc
Bước 4: Chờ cho đến khi toàn bộ Pod Slurm ở trạng thái Running. Quá trình này mất khoảng 20 phút ở lần đầu tiên cài Slurm cluster trên cụm Kubernetes, bao gồm 2 phase: phase 1 chạy job setup và phase 2 cài đặt các Pod Slurm components.
Sau khi toàn bộ các component ready, tìm IP public của login node bằng lệnh:
kubectl get svc -n fpt-hpc | grep login
Thực hiện SSH vào head node cụm Slurm:
ssh root@IP_login_svc
Nếu dùng nodeshell:
chroot /mnt/jail
sudo -i
Chạy kiểm tra:
srun --nodes=2 --gres=gpu:1 nvidia-smi -L
salloc --nodes=1 --ntasks=1 --mem=4G --time=00:20:00 --gres=gpu:1
2.2 Chạy job mẫu trên cụm Slurm
Sau khi login thành công vào cụm Slurm, bạn có thể kiểm tra hoạt động của cụm Slurm bằng việc train model minGPT theo hướng dẫn sau:
Bước 1: Clone repository pytorch/examples.
mkdir /shared
cd /shared
git clone https://github.com/pytorch/examples
Bước 2: Chuyển hướng đến folder minGPT-ddp và cài đặt các gói cần thiết.
cd examples/distributed/minGPT-ddp
pip3 install -r requirements.txt
pip3 install numpy
Nhờ cơ chế shared root, chúng ta chỉ cần chạy lệnh trên một lần, các package này sẽ tự sync trên toàn bộ các node worker khác.
Lưu ý: trong môi trường production, chúng tôi khuyến nghị việc dùng conda environment hoặc container để tạo môi trường train thay vì cài trực tiếp các package ở môi trường global như trên.
Bước 3: Edit file Slurm script.
vi mingpt/slurm/sbatch_run.sbatch
Chú ý: chỉnh path của file main.py trong file sbatch_run.sh về path của file main.py trong folder mingpt.
Bước 4: Chạy mẫu Slurm job.
sbatch mingpt/slurm/sbatch_run.sh
Bước 5: Kiểm tra.
squeue
scontrol show job job_id
cat log.out
3. Mô tả các tham số trong Custom resource của Slurm cluster
Tại phần 2 của hướng dẫn chạy Slurm trên Kubernetes, chúng tôi đã hướng dẫn bạn chỉnh các tham số quan trọng nhất. Tại phần này, chúng ta sẽ tìm hiểu thêm về các tham số/thuộc tính được định nghĩa cho một Slurm cluster. Bạn cũng có thể đọc phần comment tại file values.yaml của Slurm cluster custom resource đã tải ở phần 2 để biết thêm thông tin về các trường.
| Thuộc tính | Mô tả |
|---|---|
clusterName | Tên cụm, ví dụ "fpt-hpc" (lưu ý không đổi). |
k8sNodeFilters | Chia cụm Kubernetes ra làm hai danh sách: các node GPU (deploy Slurm worker) và các node no-gpu để deploy các thành phần khác. Trong trường hợp cụm chỉ có node GPU, hai danh sách node này có thể giống nhau. |
volumeSources | Định nghĩa các Persistent Volume Claim sẽ được dùng bởi các container đại diện cho các component (worker, login, controller node, ...) thuộc cụm Slurm. Xem ví dụ tại values.yaml. |
periodicChecks | Job chạy định kỳ để kiểm tra tình trạng của một node. Nếu node đó chứa GPU gặp vấn đề, drain node đó. |
slurmNodes | Định nghĩa về số lượng, cấu hình của các node thành phần trong một cụm Slurm (login node, worker node, ...). |
slurmNodes.accounting | Cấu hình accounting node. Tại đây chúng tôi sử dụng MariaDB Operator để tạo database; bạn cũng có thể sử dụng database ngoài (đọc thêm tại values.yaml). |
slurmNodes.controller | Cấu hình controller node — ví dụ: 1 controller node, mount 2 volume spool và jail (shared root space) vào node này. |
slurmNodes.worker | Cấu hình worker node — ví dụ: 8 worker node, mỗi node 8 GPU, mount volume jail (shared root space) vào node này. |
slurmNodes.login | Cấu hình login node — ví dụ: 2 login node, expose sshd service bằng LoadBalancer service type trong Kubernetes, sử dụng public key định nghĩa tại sshRootPublicKeys cho root user, mount các volume tương tự controller node và worker node. |
slurmNodes.exporter | Cài đặt node exporter phục vụ monitoring. |
4. Các use case thường gặp
4.1 Thêm user / login
Thêm user
Để thêm SSH key cho root, bạn chỉ cần edit Slurm cluster CR:
kubectl edit SlurmCluster fpt-hpc -n fpt-hpc
Tại phần cấu hình login node, chuyển hướng đến thuộc tính sshRootPublicKeys, thêm public key mong muốn của bạn.
Để thêm một regular user, bạn làm tương tự việc thêm user cho một Linux host:
sudo adduser user_name
Chỉnh sửa việc login
Mặc định, chúng tôi expose login node qua một Load Balancer public, điều này có thể không phù hợp với một số yêu cầu. Do vậy, bạn có thể chuyển type của LB này về private, dùng cơ chế port-forward để access vào cụm Slurm, hoặc tự customize theo ý bạn tại portal và node LB của chúng tôi.
4.2 Scale up / down worker node
Để chỉnh sửa số lượng worker node nói riêng và số lượng các node thuộc loại khác nói chung, chúng ta chỉ cần edit lại Slurm cluster CR:
kubectl edit SlurmCluster fpt-hpc -n fpt-hpc
Tại phần cấu hình worker node, chuyển hướng tới mục size và edit số lượng worker node theo mong muốn.
Lưu ý:
- Khi scale up số lượng worker node, node mới sẽ được tự động thêm vào danh sách worker node tại Slurm controller node và sẵn sàng để chạy job.
- Khi scale down node, bạn cần xóa node thủ công tại Slurm controller bằng lệnh:
scontrol delete nodeName=node_name_to_delete
- Danh sách node trong một cluster luôn là
worker-[0, (size - 1)].
4.3 Migrate Slurm cluster sang Kubernetes cluster khác
Nhờ sự linh hoạt của Kubernetes và network file storage, chúng ta có thể dễ dàng chuyển Slurm cluster từ một cụm Kubernetes này sang cụm Kubernetes khác. Việc phải làm là mounting và tạo lại jail-pvc trên cụm Slurm Kubernetes mới và thực hiện lại các bước tạo Slurm Kubernetes.
4.4 Mounting external volume vào cụm Slurm
Để mount một volume vào Slurm cluster, bạn cần tạo volume đó trước, sau đó triển khai volume đó dưới dạng PV và PVC tại Kubernetes. Ví dụ sau sử dụng dynamic provisioning để tạo PV/PVC này (trong môi trường production chúng tôi khuyến nghị sử dụng static provisioning volume để đảm bảo an toàn dữ liệu).
Bước 1: Tạo PVC.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: jail-submount-mlperf-sd-pvc
spec:
storageClassName: default
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi
Bước 2: Khai báo volume này tại Slurm cluster bằng cách edit trường volumeSource tại Slurm cluster CR.
kubectl edit SlurmCluster fpt-hpc -n fpt-hpc
volumeSources:
- name: controller-spool
persistentVolumeClaim:
claimName: "controller-spool-pvc"
readOnly: false
- name: jail
persistentVolumeClaim:
claimName: "jail-pvc"
readOnly: false
- name: mlperf-sd
persistentVolumeClaim:
claimName: "jail-submount-mlperf-sd-pvc"
readOnly: false
Bước 3: Mount các volume trên vào các node login và worker trong cụm Slurm.
Tại login node:
volumes:
jail:
volumeSourceName: "jail"
jailSubMounts:
- name: "mlcommons-sd-bench-data"
mountPath: "/mnt/data-hps"
volumeSourceName: "mlperf-sd"
Tại worker node:
volumes:
spool:
volumeClaimTemplateSpec:
storageClassName: "xplat-nfs"
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: "120Gi"
jail:
volumeSourceName: "jail"
jailSubMounts:
- name: "mlcommons-sd-bench-data"
mountPath: "/mnt/data-hps"
volumeSourceName: "mlperf-sd"
Lưu ý: mount path cần giống nhau trên các worker node và login node.
4.5 Sử dụng Docker
Trong môi trường HPC, các container runtime như Apptainer, Enroot và Pyxis được ưu tiên sử dụng hơn Docker. Tuy nhiên, các container runtime này không thuận tiện để sử dụng với những công việc build, push image, thậm chí run (không recommend Docker với Slurm) với những user đã quen sử dụng Docker.
Để hỗ trợ những user này, chúng tôi đã cài đặt Docker tại shared root volume của cụm Slurm. Như vậy, mọi node trong cụm Slurm đều có thể sử dụng Docker. Tuy nhiên, việc này yêu cầu job sử dụng toàn bộ resource của node, do các job khởi chạy bằng Docker sẽ không thể bị giới hạn tài nguyên như Apptainer.
Khuyến nghị user luôn thêm -N và --exclusive để cấp toàn bộ tài nguyên node cho job chạy bằng Docker.
4.6 Sử dụng SSH
Với những phiên bản Slurm Operator trước đây, user chỉ có thể truy cập worker node bằng việc shell trực tiếp vào node worker thông qua kubectl.
Từ version 2.0.0, Slurm Operator hỗ trợ việc SSH trên các worker node, thay vì việc phải dùng Kubernetes để shell vào worker node. User của các worker node đồng nhất với login node.
Với login node, mặc định khi SSH vào IP của load balancer, load balancer sẽ route SSH session đến một login node ngẫu nhiên.
Nếu bạn sử dụng các tool SSH như Tmux, bạn sẽ luôn muốn SSH vào một node cố định. Để luôn có thể SSH vào một node xác định, hãy sử dụng lệnh sau:
ssh -J username@public_endpoint username@login-number -i path_to_private_key