モデルの統合方法
セッションを選択して、モデルの応答を確認します。その後、システムはテストプレイグラウンドを開き、モデルを操作できます
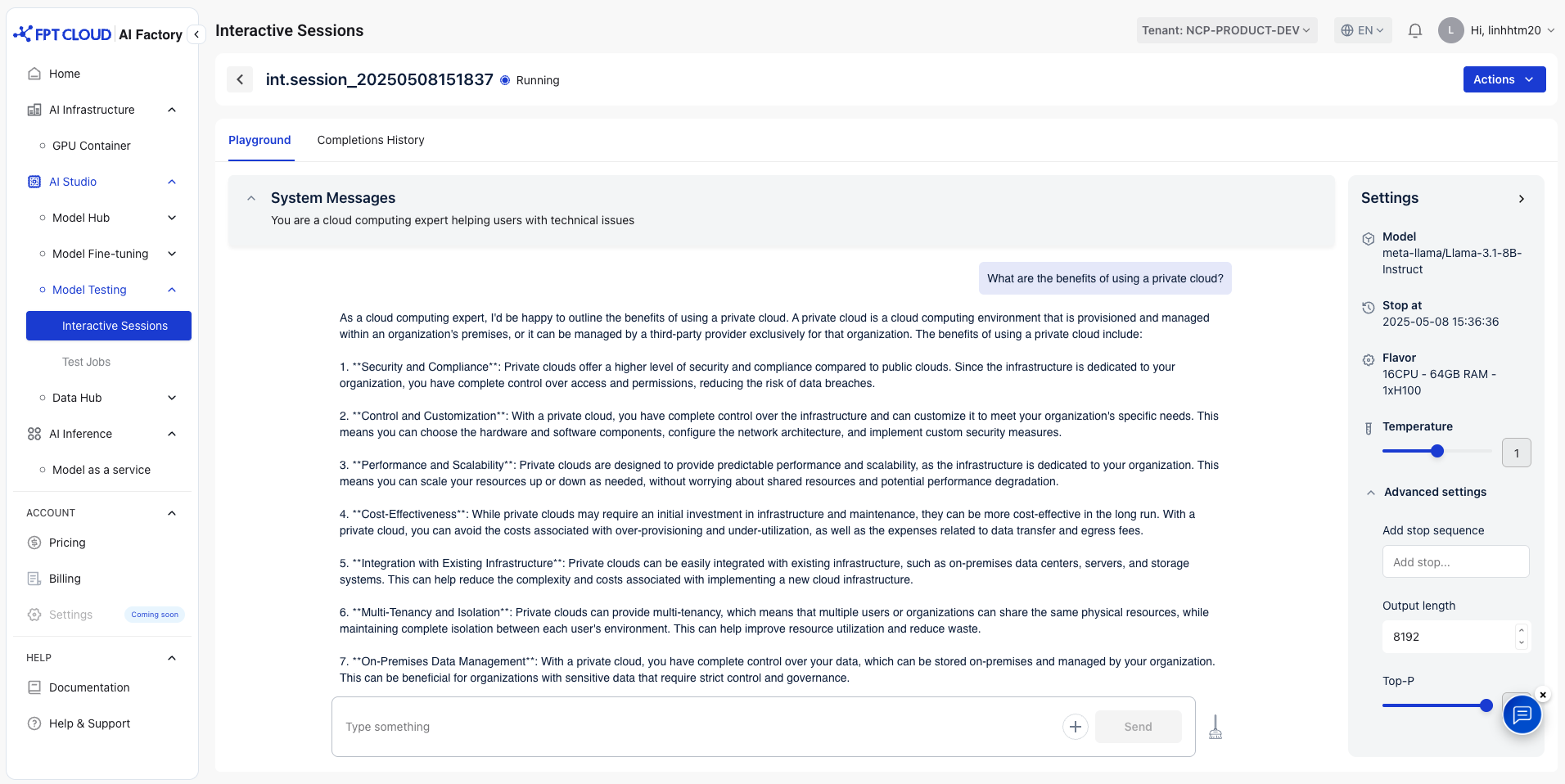
1. システムメッセージ
AI モデルの動作とトーンを設定する命令。会話全体を通じてモデルがどのように応答するかをガイドできます。
システムメッセージは、好みに基づいて変更できます。デフォルトメッセージ:「あなたは役立つアシスタントです」
例:あなたはクラウドコンピューティングの専門家であり、技術的な問題でユーザーをサポートしています。
2. ユーザーメッセージ
ユーザーがAIに提供したインプットまたは質問。モデルが会話で応答するメイン プロンプトとして機能します。
例: プライベートクラウドを使用する利点は何ですか?
VLM(Vision-Language Models)でのテスト用に、.jpegおよび**.jpg**形式での画像のアップロードをサポートしています。画像テストをサポートするモデル一覧:
-
Meta-llama/Llama-3.2-11B-Vision-Instruct
-
Qwen/Qwen2-VL-2B-Instruct
-
Qwen/Qwen2-VL-7B-Instruct
-
Qwen/Qwen2-VL-72B-Instruct
-
Qwen/Qwen2.5-VL-3B-Instruct
-
Qwen/Qwen2.5-VL-7B-Instruct
-
Qwen/Qwen2.5-VL-72B-Instruct
-
google/gemma-3-12b-it
-
google/gemma-3-27b-it
-
google/gemma-3-4b-it
3. 設定
- 温度:回答で許容される創造性は、通常0 から 2の範囲です。
デフォルト: 1
-
低温(0に近い):
-
このモデルは、より予測可能で決定論的な応答を生成します。
-
確率の高い単語やトークンを優先し、より焦点を絞った正確な アウトプットを生成します。
-
-
高温(1以上):
-
このモデルは、より創造的で多様で、予想外の応答を生成します。
-
より広範な可能な単語からサンプリングされるため、アウトプットはより 多様になります が、精度が低下する可能性があります。
-
-
詳細設定:
-
停止シーケンスの追加:停止シーケンスを使用すると、検出時にモデルを停止する 1 つ以上のシーケンスを指定することで、生成されたテキストの長さと内容を制御できます。
-
アウトプットの長さ: モデル内で生成されるテキストの長さを制御し、プロンプトに応答してモデルが生成できるトークン (単語またはサブワード) の最大数を設定します。デフォルト: 8192
-
Top-P: 生成モデルで使用され、生成されたテキストのランダム性と多様性を管理し、モデルの出力分布からサンプリングする際の温度の代替として機能します。デフォルト: 0.95
-
アウトプットモデルの設定例:
-
ストップシーケンスの追加:サードパーティ
-
出力長:1000
-
Top-P:0.95
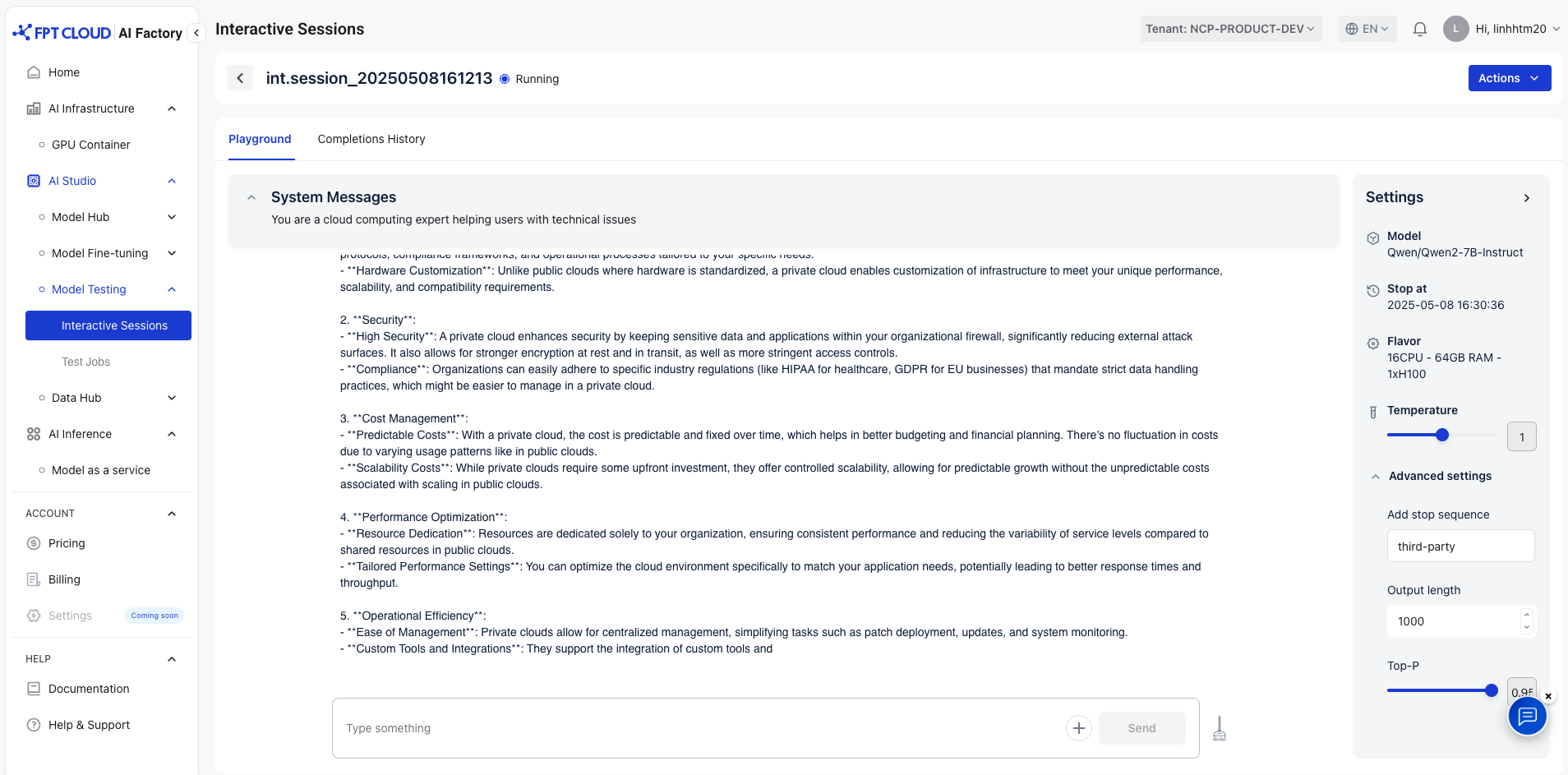
→ モデルは、停止シーケンスに遭遇するか、トークンの最大制限に達すると停止します。